Ya han comenzado las ofertas del 16 Aniversario de AliExpress con ofertas de hasta el 70% en los mejores productos y cupones de descuento:
- ASE03 o ESAS03: 3€ de descuento con EUR15 de compra mínima
- ASE05: 5€ de descuento con EUR30 de compra mínima
- ESAS06: 6€ de descuento con EUR35 de compra mínima - Código Nuevo
- ASE07: 7€ de descuento con EUR49 de compra mínima
- ESAS08: 8€ de descuento con EUR50 de compra mínima - Código Nuevo
- ASE11: 11€ de descuento con EUR79 de compra mínima
- ESAS13: 13€ de descuento con EUR89 de compra mínima - Código Nuevo
- ASE20 o ESAS20: 20€ de descuento con EUR139 de compra mínima
- ASE30 o ESAS30: 30€ de descuento con EUR209 de compra mínima
- ASE45: 45€ de descuento con EUR319 de compra mínima
- ASE60: 60€ de descuento con EUR429 de compra mínima
- ASE70: 70€ de descuento con EUR509 de compra mínima
La generación de video con inteligencia artificial (IA) ha experimentado una transformación vertiginosa: de ser un proceso complejo que requería potentes centros de datos, ha pasado a estar al alcance de dispositivos de consumo como los portátiles gaming.
Este cambio representa un gran avance tecnológico, democratizando el acceso a herramientas de creación de video que antes solo estaban disponibles para organizaciones con amplios recursos computacionales.
Evolución de la generación de video con IA
Primeros pasos y limitaciones
El desarrollo de la tecnología de generación de video con IA ha seguido una trayectoria fascinante. A principios de los años 2000, la edición de video comenzó a incorporar funciones de automatización simples, como el ajuste automático de niveles de audio o la detección de cortes en el metraje bruto. Estas herramientas se basaban en enfoques algorítmicos eficientes, pero limitados en sus capacidades.
La verdadera integración de la IA comenzó con la introducción del aprendizaje automático (machine learning, ML). Los primeros modelos de ML podían reconocer rostros en videos o seguir movimientos, facilitando aplicaciones como el seguimiento de objetos y la corrección automática de color. Sin embargo, estos primeros intentos de generación de video con IA enfrentaban grandes desafíos: los resultados solían ser toscos, con artefactos y falta de coherencia debido a las limitaciones computacionales y la falta de algoritmos avanzados.
La revolución de las redes neuronales
Con la proliferación del deep learning en la década de 2010, las posibilidades se expandieron exponencialmente. Las herramientas impulsadas por IA podían no solo reconocer objetos, sino también comprender su contexto.
El surgimiento de redes neuronales, impulsadas por avances en hardware e innovación algorítmica, marcó una nueva era para la generación de video con IA. Las arquitecturas de deep learning, caracterizadas por redes multicapa capaces de representar características jerárquicas, ofrecieron capacidades inéditas para sintetizar contenido visual realista.
Uno de los pioneros en este campo fue Ian Goodfellow, cuyo trabajo en las Redes Generativas Antagónicas (GANs) revolucionó la creación de contenido generado por IA. Las GANs, mediante un proceso competitivo entre un generador y un discriminador, sobresalen en la síntesis de imágenes y videos realistas.
Modelos texto-a-video
Un modelo texto-a-video es un modelo de aprendizaje automático que utiliza una descripción en lenguaje natural como entrada para producir un video relevante para ese texto. Los avances durante la década de 2020 en la generación de videos de alta calidad condicionados por texto han sido impulsados principalmente por el desarrollo de modelos de difusión para video.
Se han utilizado varias arquitecturas para crear modelos texto-a-video. Al igual que los modelos texto-a-imagen, estos pueden entrenarse usando Redes Neuronales Recurrentes (RNNs) como las LSTM, que han sido empleadas en modelos de transformación de píxeles y generación estocástica de video, mejorando la consistencia y el realismo. También se utilizan modelos tipo transformer, GANs, Autoencoders Variacionales (VAEs) y modelos de difusión.
Avances tecnológicos destacados
En marzo de 2023, un artículo de investigación titulado “VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation” presentó un enfoque novedoso para la generación de video. El modelo VideoFusion descompone el proceso de difusión en dos componentes: ruido base y ruido residual, compartidos entre los fotogramas para asegurar la coherencia temporal. Utilizando un modelo de difusión de imágenes preentrenado como generador base, el modelo logró generar videos de alta calidad y coherencia.
Meta, por su parte, presentó Emu Video, que utiliza su modelo Emu y una arquitectura simple basada en modelos de difusión para la generación de video a partir de texto. Este sistema unificado puede responder a diferentes entradas: solo texto, solo imagen, o ambos. El proceso se divide en dos pasos: primero, genera imágenes condicionadas por el texto, y luego genera el video condicionado tanto por el texto como por la imagen.
Grandes actores y sus aportaciones
Gigantes tecnológicos a la cabeza
Los grandes actores en el campo de la generación de video con IA son principalmente las grandes plataformas tecnológicas: Google, Meta y NVIDIA en EE. UU., y en China, Bytedance, Alibaba y Baidu. Estas empresas lideran gracias a su acceso a talento en deep learning, recursos ilimitados en la nube y grandes presupuestos.
En enero de 2024, Google anunció el desarrollo de un modelo texto-a-video llamado Lumiere, que promete integrar capacidades avanzadas de edición de video. También preparan el lanzamiento de una herramienta de generación de video llamada Veo para YouTube Shorts en 2025.
Startups innovadoras y soluciones open source
En el ámbito de las startups, empresas emergentes como PikaAI y RunwayML ofrecen herramientas para crear videos muy cortos pero de alta calidad. También existen soluciones de código abierto como Stable Video Diffusion de Stability.ai, lanzada en noviembre de 2023.
Gen-3 Alpha de Runway ofrece mayor fidelidad visual, humanos fotorrealistas y control temporal detallado, permitiendo generación ultra realista con key-framing preciso y personalización a nivel profesional.
Sora de OpenAI, aún en fase alfa, destaca por su comprensión profunda del lenguaje, visuales cinematográficos de alta calidad y videos multi-escena. Es capaz de crear videos detallados, dinámicos y expresivos, aunque sigue en desarrollo con medidas de seguridad.
El papel de NVIDIA en la democratización de la IA para video
Uno de los desarrollos más significativos en la generación de video con IA es la posibilidad de realizar estas tareas complejas en hardware de consumo, como los portátiles gaming. Las GPU GeForce RTX de NVIDIA están desempeñando un papel crucial en esta democratización, ya que contienen la misma tecnología que impulsa la innovación líder en IA.
RTX Video transforma el video de internet en video 4K HDR nítido mediante superresolución y HDR por IA, disponible en los navegadores Chrome, Edge y Firefox. Esto significa que los usuarios con portátiles equipados con RTX pueden mejorar la calidad de video en tiempo real.
¿Generar vídeos con solo 6GB de VRAM?
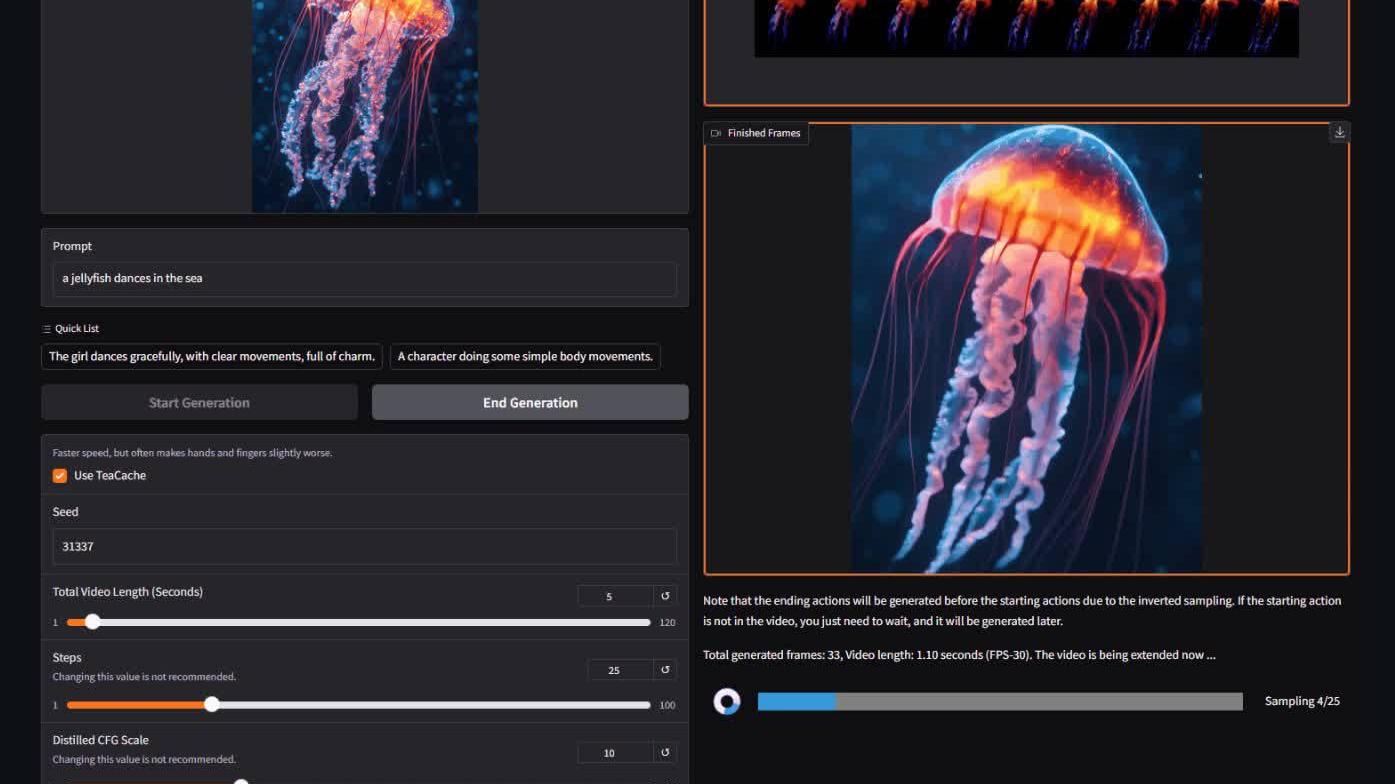
El avance es obra de Lvmin Zhang, de GitHub, y Maneesh Agrawala, de la Universidad de Stanford. El dúo ha desarrollado FramePack, una arquitectura de red neuronal que permite la difusión de vídeo de alta calidad con tan solo 6 GB de VRAM. Se trata de un logro significativo, sobre todo teniendo en cuenta el tamaño del modelo -13.000 millones de parámetros-, que le permite generar clips completos de 60 segundos a 30 FPS utilizando sólo una GPU de gama media.
La clave reside en el funcionamiento de FramePack. Los modelos tradicionales de difusión de vídeo se basan en fotogramas generados previamente para predecir el siguiente. A medida que aumenta la duración del vídeo, también lo hace el «contexto temporal» (el número de fotogramas anteriores que el modelo debe tener en cuenta), lo que se traduce en una mayor demanda de memoria. Por eso, la mayoría de los modelos necesitan 12 GB de VRAM o más para funcionar con eficacia.
FramePack le da la vuelta a la tortilla. En lugar de dejar que el uso de memoria se dispare con clips más largos, comprime los fotogramas de entrada en función de su importancia en un contexto de longitud fija, manteniendo la huella de memoria compacta y consistente independientemente de la duración del vídeo.
Esta innovación permite al modelo procesar miles de fotogramas, incluso con arquitecturas de gran tamaño, en GPU de tipo portátil. También permite entrenar con tamaños de lote comparables a los utilizados en los modelos de difusión de imágenes.
Pero FramePack no se limita a reducir las demandas de memoria, sino que también aborda el problema de la deriva, un problema habitual cuando la calidad del vídeo se degrada con el tiempo. Mediante el uso de patrones de compresión y técnicas de programación inteligentes, FramePack ayuda a mantener la coherencia visual de principio a fin.
Por si fuera poco, el modelo incluye una interfaz gráfica de usuario fácil de usar. Los usuarios pueden cargar imágenes, introducir indicaciones de texto y ver una vista previa en directo a medida que se generan los fotogramas. En una RTX 4090, las velocidades de generación optimizadas alcanzan hasta 0,6 fotogramas por segundo. Naturalmente, el rendimiento es menor en GPU menos potentes, pero incluso una RTX 3060 puede manejarlo.
Actualmente, FramePack es compatible con las GPU RTX 30, 40 y la nueva serie 50 de Nvidia, siempre que admitan los formatos de datos FP16 o BF16. Aún no hay soporte confirmado para las GPU de AMD o Intel, pero el modelo funciona en múltiples sistemas operativos, incluido Linux.
Consideraciones éticas
El despliegue de modelos texto-a-video plantea consideraciones éticas relacionadas con la generación de contenido. Estos modelos pueden crear material inapropiado o no autorizado, incluyendo contenido explícito, violencia gráfica, desinformación y la utilización de la imagen de personas reales sin consentimiento.
Garantizar que el contenido generado por IA cumpla con los estándares de uso seguro y ético es esencial, ya que puede no ser siempre fácil identificar si un video es dañino o engañoso. La capacidad de la IA para reconocer y filtrar contenido NSFW o protegido por derechos de autor sigue siendo un desafío, con implicaciones para creadores y audiencias.
El futuro de la generación de video con IA
Tendencias emergentes y predicciones
El campo de la tecnología de video con IA está en constante evolución, con innovaciones y avances continuos que amplían los límites de lo posible en la producción audiovisual. Los nuevos avances en algoritmos de aprendizaje automático, visión por computadora y procesamiento de lenguaje natural están permitiendo que los generadores de video con IA sean cada vez más sofisticados y capaces.
Estas innovaciones han llevado a una mejora en la calidad del video, opciones de personalización avanzadas y tiempos de producción más rápidos. Además, la tecnología de video con IA ha abierto el camino a la integración de realidad virtual y aumentada, creando experiencias inmersivas para los espectadores.
Se espera que los futuros desarrollos incluyan:
- Videos más largos y coherentes, con herramientas que produzcan narrativas extendidas y transiciones fluidas
- Generación en tiempo real para aplicaciones en directo
- Herramientas interactivas que permitan a los creadores colaborar con la IA para refinar escenas en tiempo real
- Personalización específica para industrias como marketing, educación y entretenimiento
- Abordar los desafíos éticos a medida que los videos se vuelven hiperrealistas, garantizando transparencia y autenticidad