Las unidades de procesamiento gráfico más conocidas como GPU se han diseñado tradicionalmente para manejar tareas de cálculo de gráficos, como procesamiento y renderizado de imágenes y vídeo, gráficos 2D y 3D, vectorización y mucho más. Sin embargo, desde hace algo más de una década las GPU cada vez se utilizan más para la computación de propósito general gracias a la llegada de los sombreadores programables y el soporte de coma flotante en los procesadores gráficos.
Los primeras funciones que se tradujeron para las GPU fueron los problemas con matrices y vectores, incluidos vectores bidimensionales, tridimensionales o cuatridimensionales. Éstos se trasladaron fácilmente a una GPU, que actúa con velocidad y soporte nativos en esos tipos de cálculos.
Para hacer esta transición, se tuvo que reformular los problemas de cálculo en términos de primitivas gráficas, que estaban soportadas por dos importantes API para procesadores gráficos: OpenGL y DirectX. Sin embargo, visto el potencial, NVIDIA desarrolló una API más optimizada llamada CUDA que permitió a los programadores sustituir los conceptos gráficos subyacentes por otros más comunes en la computación de alto rendimiento, como OpenCL y otros marcos de alto rendimiento. Esto significaba que los modernos pipelines de GPGPU podían aprovechar la velocidad de una GPU sin necesidad de una conversión completa y explícita de los datos a una forma gráfica.
Años más tarde, en 2016, AMD lanzó su propia plataforma de computación de propósito general bautizada como Radeon Open Compute Ecosystem (ROCm). ROCm está dirigida principalmente a GPU profesionales discretas, como la línea Radeon Pro de AMD. Sin embargo, el soporte oficial es más amplio y se extiende a los productos de consumo, incluidas las GPU de juegos.
A diferencia de CUDA, la API de software ROCm puede aprovechar varios dominios, como la GPGPU de propósito general, la computación de alto rendimiento (HPC) y la computación heterogénea. También ofrece varios modelos de programación, como HIP (programación basada en el núcleo de la GPU), OpenMP/Message Passing Interface (MPI) y OpenCL. También son compatibles con microarquitecturas, incluidas RDNA y CDNA, para una miríada de aplicaciones que abarcan desde la IA y la computación de borde hasta el IoT/IIoT.
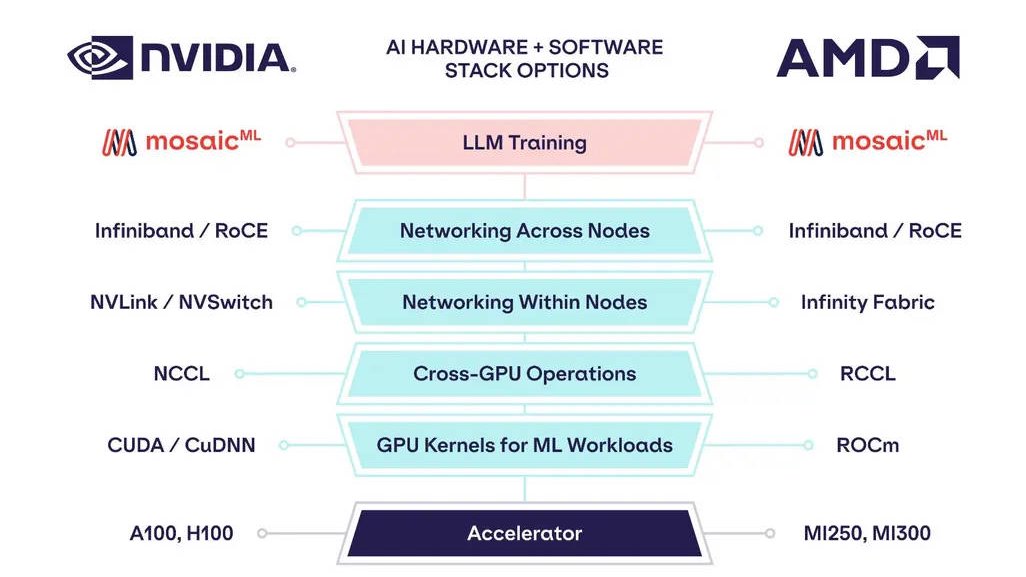
Nvidia CUDA

La mayoría de las tarjetas de las series Tesla y RTX de NVIDIA vienen equipadas con unos núcleos CUDA diseñados para realizar múltiples cálculos al mismo tiempo. Estos núcleos son similares a los de la CPU, pero vienen empaquetados en la GPU y pueden procesar datos en paralelo. Puede haber miles de estos núcleos integrados en la GPU, lo que los convierte en sistemas paralelos increíblemente eficientes capaces de descargar las tareas centradas en la CPU directamente en la GPU.

Como ocurre con la mayoría de las API, los kits de desarrollo de software (SDK) y las API de software, NVIDIA proporciona librerías, directivas de compilador y extensiones para los lenguajes de programación más populares mencionados anteriormente, lo que facilita y agiliza la programación. Entre ellas se incluyen cuSPARCE, la compilación en tiempo de ejecución NVRTC, GameWorks Physx, el soporte de GPU multi-instancia MIG, cuBLAS y muchas otras.
El uso actual de la arquitectura CUDA que va más allá de la IA e incluye computación distribuida, química, dinámica molecular, análisis médico (CTI, MRI y otras aplicaciones de escaneo de imágenes), cifrado y mucho más.
ROCm de AMD

La plataforma ROCm de AMD es similar a CUDA, sólo que es de código abierto y es compatible con varias marcas de tarjetas gráficas para acelerar las tareas de cálculo. Por supuesto, muchas tarjetas de AMD vienen equipadas con núcleos de cálculo, aceleradores de rayos (Ray tracing) y procesadores de flujo que aprovechan la arquitectura RDNA para el procesamiento paralelo, lo que incluye GPGPU, HPC, HIP (modelo de programación similar a CUDA), MPI y OpenCL.
La plataforma ROCm de AMD está diseñada para escalar, lo que significa que admite la computación multi-GPU dentro y fuera de la comunicación servidor-nodo a través del acceso remoto directo a memoria (RDMA), que proporciona la capacidad de acceder directamente a la memoria del host sin intervención de la CPU. Así, cuanto mayor sea la memoria RAM del sistema, mayores serán las cargas de procesamiento que podrá gestionar ROCm.

ROCm también simplifica el stack cuando el controlador incorpora directamente soporte RDMA peer-sync, lo que facilita el desarrollo de aplicaciones. Además, incluye ROCr System Runtime, que es independiente del lenguaje y aprovecha la API HAS (heterogeneous system architecture) Runtime, proporcionando una base para ejecutar lenguajes de programación como HIP y OpenMP.
Al igual que CUDA, ROCm es una solución ideal para aplicaciones de IA, ya que algunos frameworks de aprendizaje profundo ya admiten un backend ROCm (por ejemplo, TensorFlow, PyTorch, MXNet, ONNX, CuPy, etc.). Según AMD, cualquier fabricante de CPU/GPU puede aprovechar las ventajas de ROCm, ya que no se trata de una tecnología propietaria.
La compañía ofrece una serie de librerías, complementos y extensiones para ampliar la funcionalidad de ROCm, incluida una solución (HCC) para el lenguaje de programación C++ que permite a los usuarios integrar la CPU y la GPU en un único archivo.
El conjunto de funciones de ROCm es muy amplio e incorpora soporte multi-GPU para memoria virtual de grano grueso, capacidad para procesar concurrencia, señales HSA y atómicas, DMA y colas en modo usuario. También ofrece un cargador estandarizado y formatos de código-objeto, soporte de compilación dinámica y offline, funcionamiento P2P multi-GPU con soporte RDMA, API de rastreo y recopilación de eventos, y APIs y herramientas de gestión del sistema. Además, existe un ecosistema de terceros cada vez más amplio que empaqueta distribuciones ROCm personalizadas para cualquier aplicación en multitud de sabores de Linux.
Resumen
Nvidia tuvo mucha visión y se adelantó a la competencia con CUDA… Y eso le ha servido para convertirse en una de las compañías más valiosas del mundo (en capitalización del mercado).
AMD por su lado, ha llegado muy tarde con ROCm y se encuentra con muchas barreras de entrada porque todo está diseñado para CUDA. Sin embargo, el alto precio de las tarjetas gráficas de Nvidia (las GPU H100 de Nvidia se venden a más de 30.000 dólares y se rumorea que a Nvidia le cuesta 3.000 dólares fabricarlas) está hartando a muchas empresas. Además, el software propietario CUDA no levanta las simpatías de muchos desarrolladores. Por eso, la influencia de CUDA en el mundo de la IA está disminuyendo más rápidamente de lo que podría pensarse.
Actualmente el rendimiento de ROCm es muy bueno y AMD está echándolo todo para proporcionar el mejor soporte posible. Por eso, la tendencia actual es que muchos desarrolladores están pasándose a ROCm… Lo que, personalmente, creo que es una buena noticia porque todo es de código abierto y agnóstico del hardware.
