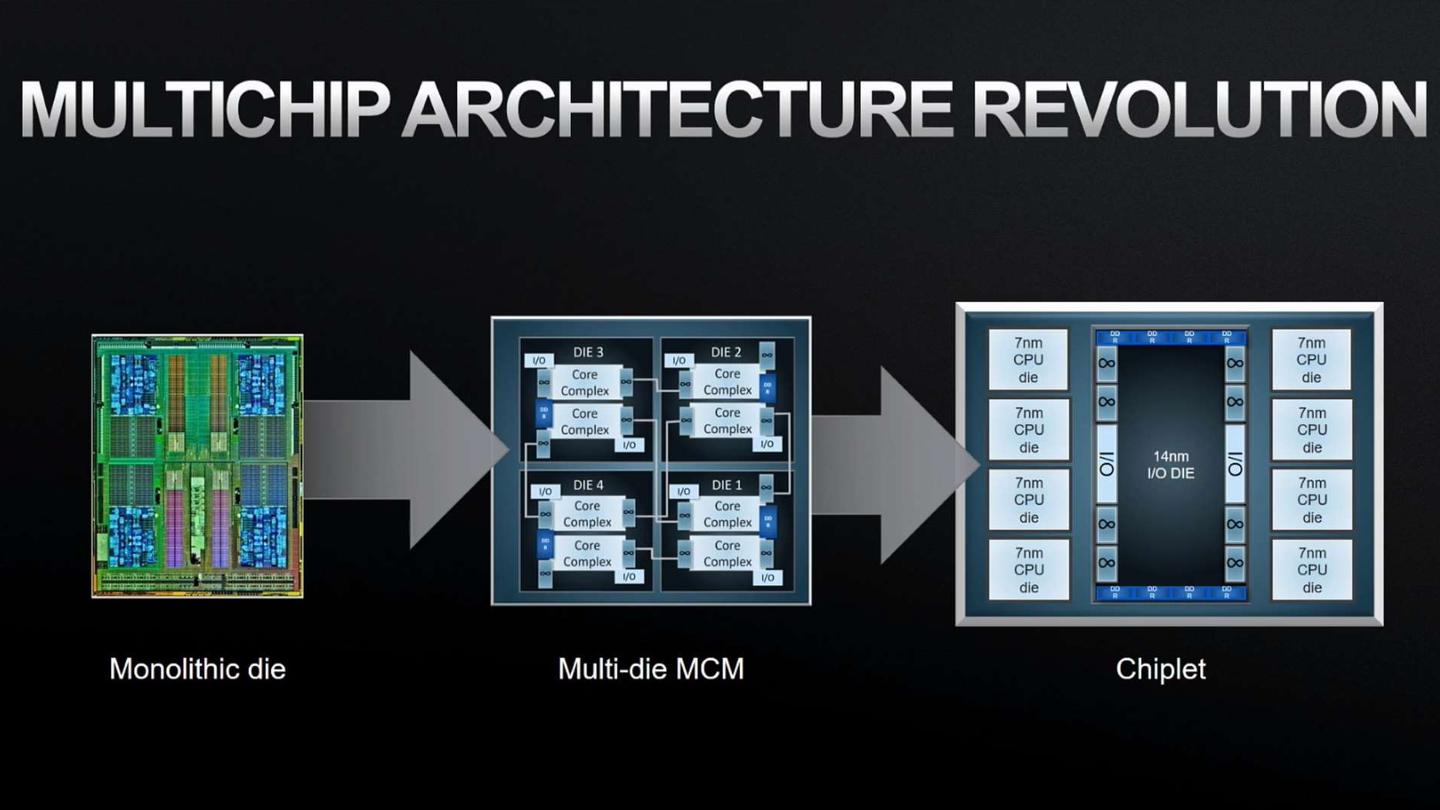
La ley de Moore dice que cada dos años se duplica el número de transistores en un microprocesador. Pero, aunque se ha cumplido durante casi 50 años, desde el año 2012 nos hemos alejado un poco de las predicciones: el progreso de los procesadores se ha ralentizado.

Esto es debido a que la construcción cada vez más pequeña de los transistores conlleva un aumento de la complejidad en el proceso de fabricación. Y sino que se lo digan a Intel y su lucha con los 10 nm (nanómetros).ref
AMD, aunque no ha tenido tantos problemas con la fabricación en 10 nm, también se ha dado de bruces con los costes de fabricación. En el siguiente gráfico podemos ver cómo los costes se dispararon cuando los transistores disminuyen de los 14 nm.

¿Qué son los chiplets?
Para entender bien por qué los fabricantes de procesadores han recurrido a los chiplets, primero debemos profundizar en cómo se fabrican estos dispositivos. Las CPU y GPU empiezan su vida como grandes discos de silicio ultrapuro, normalmente de algo menos de 300 mm de diámetro y 1 mm de grosor.
Esta oblea de silicio se somete a una secuencia de intrincados pasos que dan como resultado múltiples capas de distintos materiales: aislantes, dieléctricos y metales. Los patrones de estas capas se crean mediante un proceso llamado fotolitografía, en el que la luz ultravioleta se proyecta a través de una versión ampliada del patrón (una máscara), y posteriormente se encoge mediante lentes hasta alcanzar el tamaño requerido.
Una vez terminada, la oblea se somete a pruebas con una sonda aplicada a cada chip. Los resultados del examen eléctrico informan a los ingenieros sobre la calidad del procesador en función de una larga lista de criterios. Esta etapa inicial, conocida como chip binning, ayuda a determinar el “grado” del procesador.
Por ejemplo, si el chip está destinado a ser una CPU, cada pieza debe funcionar correctamente, dentro de una gama determinada de velocidades de reloj a un voltaje específico. Cada sección de la oblea se clasifica en función de los resultados de las pruebas.
Una vez terminada, la oblea se corta en piezas individuales, o “troqueles”, que son viables para su uso. Estos troqueles se montan en un sustrato similar a una placa base especializada. El procesador se vuelve a empaquetar (por ejemplo, con un disipador de calor) antes de que esté listo para su distribución.
La secuencia completa puede llevar semanas de fabricación y empresas como TSMC y Samsung cobran tarifas elevadas por cada oblea, entre 3.000 y 20.000 dólares según el nodo de proceso que se utilice.
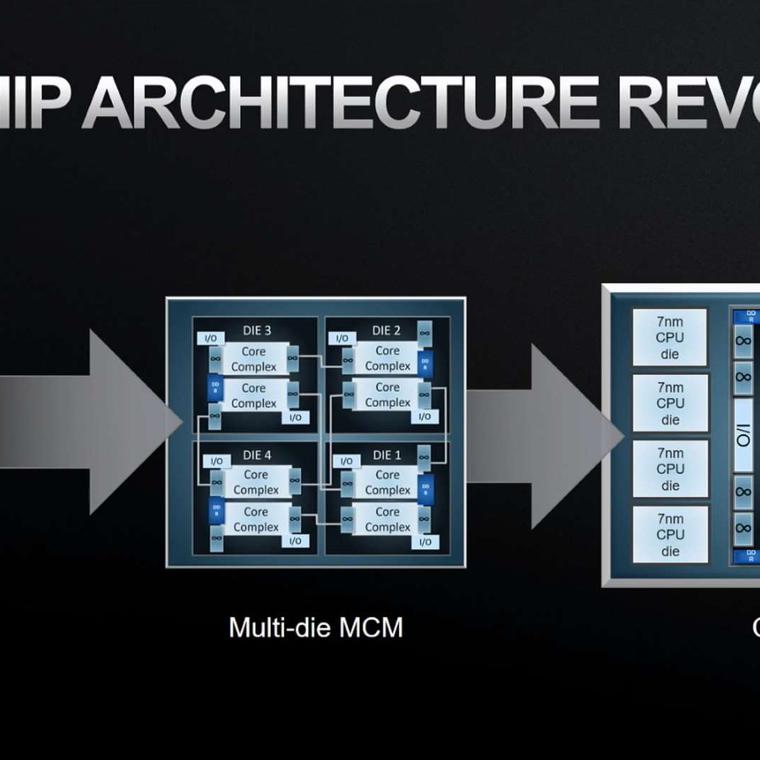
Para abaratar los costes los nuevos procesadores estarán hechos de partes más pequeñas, llamadas chiplets, en vez de un chip único y grande.
- Los chiplets son componentes independientes que se agrupan para construir un chip más grande.
- Los chiplets son más pequeños y son más fáciles y baratos de fabricar.

Hasta ahora, los procesadores se fabricaban con arquitectura monolítica. El diseño monolítico significa que todos los componentes del procesador (ALU, AGU, CU, cache, etc.) están fabricados juntos y en contacto. Por lo que, si alguno de esos circuitos falla, todos quedan inservibles.
A medida que los transistores se han hecho más pequeños, el número de fallos por oblea ha ido aumentando; haciendo que el coste de fabricación sea cada vez mayor (como hemos visto).
Por otro lado, como los chiplets son fabricados de manera independiente del resto de componentes del procesador, si un chiplet falla no hay que tirar todo el procesador, se sustituye por otro y solucionado. Lógicamente, es más fácil construir una parte más pequeña sin fallos que el conjunto total.
Una ventaja más de la fabricación mediante chiplets es que se puede mejorar el binning de los núcleos. Esto significa que podemos juntar los núcleos de manera más homogénea.
Otro problema de la arquitectura monolítica es que la frecuencia final del procesador viene limitada por la frecuencia máxima del núcleo más lento del procesador. De esta manera, si un procesador tiene varios núcleos y todos alcanzan los 4,5 GHz menos uno que solo alcanza los 4 GHz, el procesador tendrá que funcionar a 4 GHz. Los chiplets permiten al fabricante juntar los núcleos de manera más homogénea (juntar todos los núcleos buenos con los buenos y los malos con los malos) para conseguir un mejor rendimiento económico.
Por último, los circuitos del interior de los chips no son todos iguales:
- Lógica: se encarga de los datos, las matemáticas y la toma de decisiones
- Memoria: normalmente SRAM, que almacena datos para la lógica
- Analógicos: circuitos que gestionan las señales entre el chip y otros dispositivos
Mientras que los circuitos lógicos siguen reduciéndose con cada gran avance en la tecnología de nodos de proceso, los circuitos analógicos apenas han cambiado y los de memoria también está empezando a alcanzar un límite por lo que combinar diferentes chips fabricados con diferentes nodos es la manera más eficiente de construirlos.
Inconvenientes
El mayor problema que tiene la fabricación mediante chiplets es que los diferentes circuitos no se encuentran en contacto directo, por lo que aumenta el tiempo que tardan los datos en viajar de un chiplet a otro. Es lo que se conoce como lag o latencia.
Esta latencia puede disminuir el rendimiento global del procesador.
¿Desde cuándo se usan los chiplets?
En 1995, Intel lanzó el sucesor de su procesador P5 original, el Pentium II. Lo que lo diferenciaba de lo habitual en aquella época era que, bajo la carcasa de plástico, había una placa de circuitos que contenía dos chips: el chip principal, que contenía toda la lógica de procesamiento y los sistemas analógicos, y uno o dos módulos SRAM independientes que servían de caché de nivel 2. Intel fabricaba el chip principal, pero no el Pentium II.
Aunque Intel siguió haciendo sus pinitos con los chips múltiples en el mismo encapsulado, se aferró en gran medida al denominado enfoque monolítico para los procesadores, es decir, un chip para todo. Para la mayoría de los procesadores, no había necesidad de más de una matriz, ya que las técnicas de fabricación eran lo suficientemente competentes (y asequibles) como para mantener la sencillez.
Sin embargo, otras empresas estaban más interesadas en seguir un enfoque multichip, sobre todo IBM. En 2004, era posible adquirir una versión de 8 chips de la CPU de servidor POWER4 que incluía cuatro procesadores y cuatro módulos de caché, todos montados dentro del mismo cuerpo (lo que se conoce como módulo multichip o enfoque MCM).
Por aquel entonces, empezó a aparecer el término “integración heterogénea” (HI - heterogeneous integration), en parte debido al trabajo de investigación realizado por DARPA (Defense Advanced Research Project Agency). El objetivo de la HI es separar las distintas secciones de un sistema de procesamiento, fabricarlas individualmente en los nodos más adecuados para cada una y combinarlas después en un mismo paquete.
Hoy en día, esto se conoce mejor como sistema en paquete (SiP - System-in-package ) y ha sido el método estándar para equipar los smartwatches con chips desde sus inicios. Por ejemplo, el Apple Watch Series 1 alberga una CPU, algo de DRAM y NAND Flash, varios controladores y otros componentes dentro de una misma estructura.
Se puede conseguir una configuración similar colocando diferentes sistemas en una sola matriz (lo que se conoce como sistema en chip o SoC). Sin embargo, este enfoque no permite aprovechar los diferentes precios de los nodos, ni todos los componentes pueden fabricarse de este modo.
Para un proveedor de tecnología, utilizar la integración heterogénea para un producto nicho es una cosa, pero emplearla para la mayor parte de su cartera es otra. Esto es precisamente lo que hizo AMD con su gama de procesadores. En 2017, el gigante de los semiconductores lanzó su arquitectura Zen en forma de CPU de sobremesa Ryzen de un solo chip. Varios meses después, debutaron dos líneas de productos multichip, Threadripper y EPYC, esta última con hasta cuatro dies.
Con el lanzamiento de Zen 2 dos años más tarde, AMD adoptó por completo los chilpsets (HI, MCM, SiP… llámalo como quieras). Desplazaron la mayoría de los componentes analógicos fuera del procesador y los colocaron en una matriz independiente. Éstos se fabricaron en un nodo de proceso más sencillo y barato, mientras que para el resto de la lógica y la caché se utilizó uno más avanzado.
Más pequeño es mejor
Para entender exactamente por qué AMD eligió esta dirección, examinemos la siguiente imagen. En ella se muestran dos CPU de la serie Ryzen 5: la 2600 a la izquierda, que emplea la denominada arquitectura Zen+, y la 3600 con tecnología Zen 2 a la derecha.

- El único chip del 2600 alberga ocho núcleos, aunque dos de ellos están desactivados en este modelo concreto.
- Este es también el caso del 3600, pero aquí podemos ver que hay dos troqueles en el paquete: el Core Complex Die (CCD) en la parte superior, que alberga los núcleos y la caché, y el Input/Output Die (IOD) en la parte inferior, que contiene todos los controladores (para memoria, PCI Express, USB, etc.) y las interfaces físicas.
Dado que las dos CPU Ryzen encajan en el mismo zócalo de placa base, las dos imágenes son esencialmente a escala. A primera vista, podría parecer que los dos chips del 3600 tienen una superficie combinada mayor que el único chip del 2600, pero las apariencias engañan.
Si comparamos directamente los chips que contienen los núcleos, en el CCD Zen 2, muy poca área del chip está dedicada a los sistemas analógicos; está compuesta casi en su totalidad por lógica y SRAM.
El área combinada de los chips en el modelo más reciente es menor, y también cuenta con el doble de caché L3, que admite memoria más rápida y PCI Express. Sin embargo, lo mejor del enfoque del chiplet es que el tamaño compacto del CCD hizo posible que AMD metiera otro en el paquete. Este desarrollo dio origen a la serie Ryzen 9, que ofrece modelos de 12 y 16 núcleos para PC de sobremesa.
Mejor aún, al utilizar dos chips más pequeños en lugar de uno grande, cada oblea puede producir potencialmente más troqueles. En el caso del CCD Zen 2, una sola oblea de 12 pulgadas (300 mm) puede producir hasta un 85% más de chips que en el modelo Zen+.
Además, cuanto más pequeño es el trozo que se extrae de una oblea, menos probabilidades hay de encontrar defectos de fabricación (ya que tienden a distribuirse aleatoriamente por el disco), por lo que, teniendo todo esto en cuenta, el enfoque chiplet no sólo dio a AMD la posibilidad de ampliar su cartera, sino que lo hizo de forma mucho más rentable: los mismos CCD pueden utilizarse en varios modelos y cada oblea produce cientos de ellos.
Por tanto, los chiplets fueron tan ventajosos que le dieron bastante ventaja a AMD, aunque ahora Intel está adoptándolos también. En su caso Intel utiliza el término “tiles” en lugar de “chiplets” y tienen varias partes:
- Cálculo: contiene todos los núcleos y la caché L2
- GFX: alberga la GPU integrada
- SOC: incorpora la caché L3, PCI Express y otros controladores
- IO: aloja las interfaces físicas para la memoria y otros dispositivos

Hay conexiones de alta velocidad y baja latencia entre el SOC y las otras tres placas, y todas ellas están conectadas a otra matriz, conocida como intercalador. Este intercalador suministra energía a cada chip y contiene las trazas entre ellos. A continuación, el intercalador y las cuatro placas se montan en una placa adicional para poder empaquetar todo el conjunto.
A diferencia de Intel, AMD no utiliza ninguna matriz de montaje especial, sino que dispone de su propio sistema de conexión, conocido como Infinity Fabric, para gestionar las transacciones de datos de los chips. El suministro de energía se realiza a través de un paquete bastante estándar, y AMD también utiliza menos chiplets. Entonces, ¿por qué el diseño de Intel es así?
Uno de los problemas del enfoque de AMD es que no es muy adecuado para el sector ultramóvil de bajo consumo. Por eso AMD sigue utilizando CPU monolíticas para ese segmento. El diseño de Intel les permite mezclar y combinar diferentes placas para adaptarse a una necesidad específica. Por ejemplo, los modelos económicos para portátiles asequibles pueden usar tiles mucho más pequeños en todas partes, mientras que AMD sólo tiene un tamaño de chip para cada propósito.
El inconveniente del sistema de Intel es que es complejo y caro de producir, aunque es demasiado pronto para predecir cómo afectará esto a los precios de venta al público. Sin embargo, ambas empresas de CPU están plenamente comprometidas con el concepto de chiplet. Una vez que todas las partes de la cadena de fabricación se diseñen en torno a él, los costes deberían disminuir.
¿Chiplets en las tarjetas gráficas?
En cuanto a las GPU, contienen relativamente poca circuitería analógica en comparación con el resto de la matriz, pero la cantidad de SRAM en su interior no deja de aumentar. Por eso, AMD aplicó sus conocimientos sobre chipsets a su última serie Radeon 7000, con las GPU Radeon RX 7900, compuestas por varios chips: uno grande para los núcleos y la caché L2, y cinco o seis chips diminutos, cada uno con una porción de caché L3 y un controlador de memoria.
Al desplazar estas piezas fuera de la matriz principal, los ingenieros pudieron aumentar significativamente la cantidad de lógica sin necesidad de utilizar los nodos de proceso más avanzados para mantener el tamaño de los chips bajo control. Sin embargo, el cambio no reforzó la amplitud de la cartera de gráficos, aunque probablemente sí ayudó a mejorar los costes generales.
En la actualidad, Intel y Nvidia no muestran signos de seguir los pasos de AMD en el diseño de sus GPU. Ambas compañías utilizan TSMC para todas las tareas de fabricación y parecen contentarse con producir chips extremadamente grandes, repercutiendo el coste en los consumidores.
Sin embargo, dado que los ingresos del sector gráfico no dejan de disminuir, es posible que en los próximos años todos los fabricantes de GPU adopten el mismo camino.
Futuro
A pesar de los enormes avances tecnológicos en la fabricación de semiconductores, existe un límite definitivo a la reducción del tamaño de cada componente. Para seguir mejorando el rendimiento de los chips, los ingenieros tienen esencialmente dos vías:
- Añadir más lógica, con la memoria necesaria para soportarla
- Aumentar las velocidades de reloj internas
En cuanto a esto último, la CPU media no ha variado significativamente en este aspecto desde hace años. El procesador FX-9590 de AMD, de 2013, podía alcanzar los 5 GHz en determinadas cargas de trabajo, mientras que la velocidad de reloj más alta en sus modelos actuales es de 5,7 GHz (con el Ryzen 9 7950X).
Sin embargo, lo que sí ha cambiado es la cantidad de circuitos y SRAM. El mencionado FX-9590 tenía 8 núcleos (y 8 hilos) y 8 MB de caché L3, mientras que el 7950X3D presume de 16 núcleos, 32 hilos y 128 MB de caché L3. Las CPU de Intel también se han ampliado en términos de núcleos y SRAM.
La primera GPU de sombreado unificado de Nvidia, la G80 de 2006, constaba de 681 millones de transistores, 128 núcleos y 96 kB de caché L2 en un chip de 484 mm2 de superficie. Si avanzamos hasta 2022, cuando se lanzó el AD102, ahora cuenta con 76.300 millones de transistores, 18.432 núcleos y 98.304 kB de caché L2 en un área de 608 mm2.
En 1965, Gordon Moore, cofundador de Fairchild Semiconductor, observó que en los primeros años de fabricación de chips, la densidad de componentes dentro de una matriz se duplicaba cada año para un coste de producción mínimo fijo. Esta observación se conoció como la Ley de Moore y más tarde se interpretó como “el número de transistores en un chip se duplica cada dos años”, basándose en las tendencias de fabricación.
La Ley de Moore ha seguido siendo una descripción razonablemente exacta de la progresión de la industria de semiconductores durante casi seis décadas. Los enormes avances en lógica y memoria de las CPU y las GPU se han conseguido gracias a continuas mejoras en los nodos de proceso, con componentes cada vez más pequeños a lo largo de los años. Sin embargo, esta tendencia no puede continuar para siempre, independientemente de las nuevas tecnologías que surjan.
En lugar de esperar a que se alcance este límite, empresas como AMD e Intel han recurrido a los chiplets, explorando diversas formas de combinarlos para seguir avanzando en la creación de procesadores cada vez más potentes.
Dentro de unas décadas, el PC medio podría albergar CPUs y GPUs del tamaño de la mano, pero si quitamos el disipador de calor encontraremos un montón de chips diminutos, no tres ni cuatro, sino docenas de ellos, todos ingeniosamente colocados y apilados entre sí. Los chiplets no han hecho más que empezar…
Fuentes
